

说明
您可以配合实际操作视频教程一起学习:https://www.bilibili.com/video/BV13T4y1f7Cu/
官方Yolov5文档:https://github.com/ultralytics/yolov5/
官方Docker:docker.io/ultralytics/yolov5:v4.0
MLU SDK版本:1.7.0
MLU PYTORCH版本:1.3.0
【以下版本在v4版本上完成(v5和v4类似)】
高版本PyTorch降级到低版本PyTorch
为什么要做这一步?
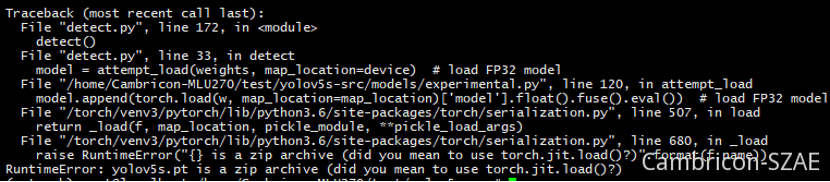
目前训练,已经在1.8.x的PyTorch上进行,但是MLU的PyTorch还是1.3.0版本。
高版本的PyTorch带有zip压缩模型功能,但是在1.3.0上不支持,如果在1.3.0的版本上直接打开高版本的PT,会出现报错。
利用官方的Docker来简化我们的环境搭建工作
官方Docker:docker.io/ultralytics/yolov5:v4.0
搭建高版本(1.18) PyTorch环境
#/bin/bash
set -x
export MY_CONTAINER="hub_yolov5_v4_0"
num=`docker ps -a|grep "$MY_CONTAINER"|wc -l`
echo $num
echo $MY_CONTAINER
if [ 0 -eq $num ];then
#xhost +
nvidia-docker run -it --rm --gpus=all --ipc=host --name $MY_CONTAINER \
docker.io/ultralytics/yolov5:v4.0 /bin/bash
else
docker start $MY_CONTAINER
docker exec -ti --env COLUMNS=`tput cols` --env LINES=`tput lines` $MY_CONTAINER /bin/bash
fi
这里启动 docker.io/ultralytics/yolov5:v4.0 镜像
降PyTorch的版本
进入容器后,到目录 /usr/src/app

修改detect.py
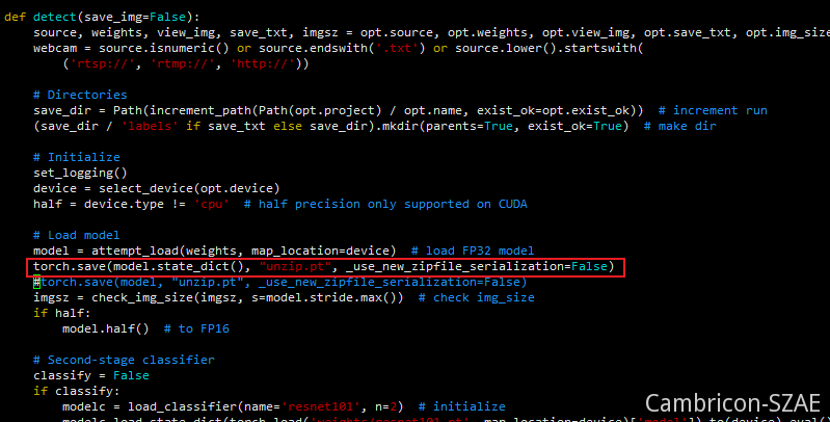
torch.save(model.state_dict(), "unzip.pt", _use_new_zipfile_serialization=False)
下载weights文件:
如果默认执行,会默认下载5.0版本的,这里我们统一用的4.0版本,为了避免出现奇怪的问题,我们手动下载4.0的版本。
https://github.com/ultralytics/yolov5/releases/tag/v4.0
运行
python detect.py --device cpu --weights yolov5.pt
生成unzip.pt文件,这个pt可以放到MLU PyTorch使用。
到此,PT降版本工作完成。
增加算子
修改/workspace/neuware_sdk_ubuntu_prebuild/venv/lib/python3.6/site-packages/torch/nn/modules/activation.py,添加SiLU, HardTanh激活函数
class Hardswish(Module): # export-friendly version of nn.Hardswish()
@staticmethod
def forward(x):
# return x * F.hardsigmoid(x) # for torchscript and CoreML
return x * F.hardtanh(x + 3, 0., 6.) / 6. # for torchscript, CoreML and ONNX
class SiLU(Module): # export-friendly version of nn.SiLU()
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
修改/workspace/neuware_sdk_ubuntu_prebuild/venv/lib/python3.6/site-packages/torch/nn/modules/__init__.py,注册SiLU, HardTanh激活函数
1,from .activation import 中添加SiLU, Hardswish,
2,__all__ = 中添加'SiLU', 'Hardswish',
MLU移植工作
首先请确认您安装的是MLU SDK 1.7.0版本,具体的移植步骤如下:
1. 环境搭建(云平台已搭好)
使用镜像:yellow.hub.cambricon.com/pytorch/pytorch:0.15.0-ubuntu16.04
#/bin/bash
export MY_CONTAINER="Cambricon-MLU270-v1.7.0-pytorch"
num=`docker ps -a|grep "$MY_CONTAINER"|wc -l`
echo $num
echo $MY_CONTAINER
if [ 0 -eq $num ];then
xhost +
docker run -e DISPLAY=unix$DISPLAY --device /dev/cambricon_dev0 --net=host --pid=host -v /sys/kernel/debug:/sys/kernel/debug -v /tmp/.X11-unix:/tmp/.X11-unix -it --privileged --name $MY_CONTAINER -v $PWD/Cambricon-MLU270/:/home/Cambricon-MLU270 \
-v $PWD/../tar_package/datasets:/home/Cambricon-MLU270/datasets \
-v $PWD/../tar_package/models:/home/Cambricon-MLU270/models \
yellow.hub.cambricon.com/pytorch/pytorch:0.15.0-ubuntu16.04 /bin/bash
else
docker start $MY_CONTAINER
#sudo docker attach $MY_CONTAINER
docker exec -ti $MY_CONTAINER /bin/bash
fi
-v部分自定义
2. 下载yolov5:v4.0版本
git clone https://github.com/ultralytics/yolov5.git
git checkout v4.0
目录为yolov5
3. 激活MLU PyTorch
source /torch/venv3/pytorch/bin/activate
4. 修改部分代码
在yolov5的目录下,需要修改部分代码
1)引入库
(pytorch) root@localhost:/home/Cambricon-MLU270/test/yolov5s-src# git diff
diff --git a/models/experimental.py b/models/experimental.py
index 2dbbf7f..c83c685 100644
--- a/models/experimental.py
+++ b/models/experimental.py
@@ -1,4 +1,6 @@
# This file contains experimental modules
+import matplotlib
+matplotlib.use('Agg')
import numpy as np
import torch
在 models/experimental.py,头部增加 import matplotlib 和 matplotlib.use('Agg') 两行
2). 修改读取model代码
def attempt_load(weights, map_location=None):
from models.yolo import Model
model = Model('./models/yolov5s.yaml')
state_dict = torch.load(weights[0], map_location='cpu')
model.float().fuse().eval()
model.load_state_dict(state_dict, strict=False)
model.float().fuse().eval()
return model
这里默认使用yolov5s,所以固定载入 ./models/yolov5s.yaml
3)验证
python detect.py --device cpu --weights yolov5s-v4.pt
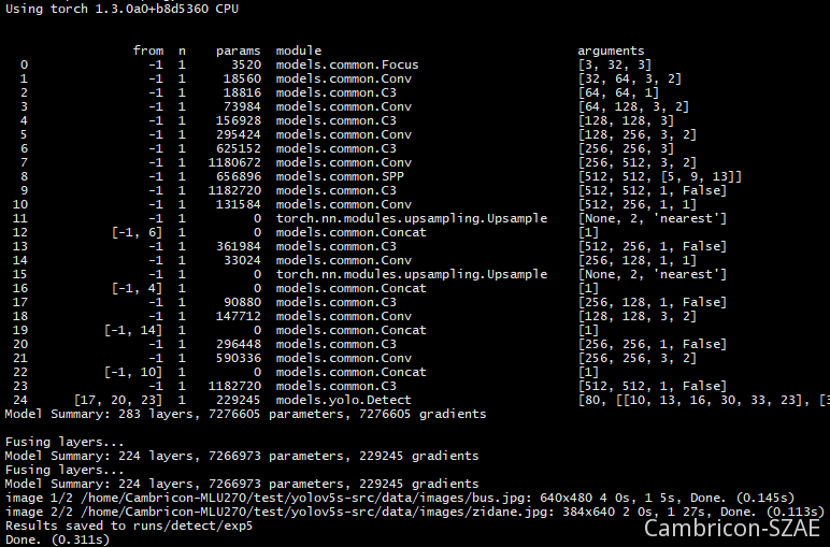
到此,官方的pt模型,能在MLU PYTORCH上运行了。
量化
1. 在detect.py中,在 Run inference上增加代码
import torch_mlu
import torch_mlu.core.mlu_quantize as mlu_quantize
import torch_mlu.core.mlu_model as ct
...
global quantized_model
if opt.cfg == 'qua':
qconfig = {'iteration':2,'firstconv':False}
quantized_model = mlu_quantize.quantize_dynamic_mlu(model, qconfig, dtype='int8', gen_quant=True)
# Run inference
t0 = time.time()
img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img
....
# Inference
t1 = time_synchronized()
if opt.cfg == 'cpu':
pred = model(img, augment=opt.augment)[0]
print('run cpu')
elif opt.cfg == 'qua':
pred = quantized_model(img)[0]
torch.save(quantized_model.state_dict(), 'yolov5s_int8.pt')
print('run qua')
if __name__ == '__main__':
...
parser.add_argument('--cfg', default='cpu', help='qua and off')
parser.add_argument('--jit', type=bool,default=False)
...
2. 执行
python detect.py --weights yolov5s-v4.pt --cfg qua
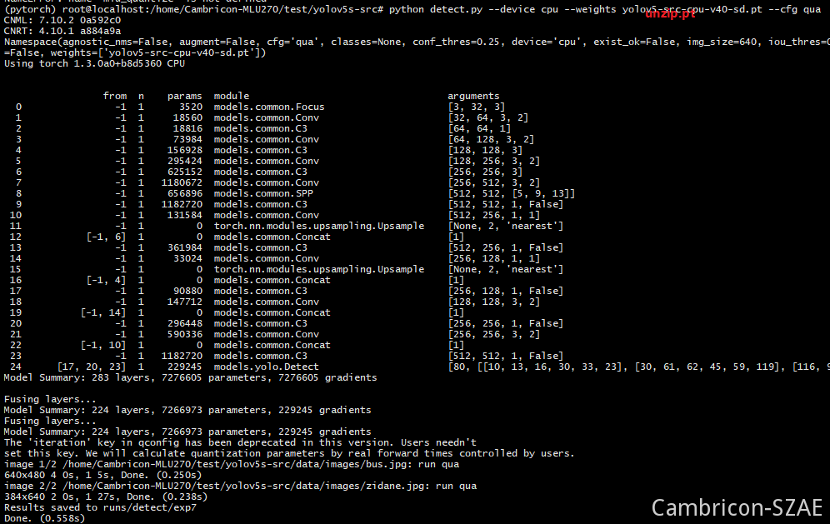
torch.save(quantized_model.state_dict(), 'yolov5s_int8.pt')
这句会保存一个量化的pt
逐层
由于每一层都需要跑在mlu上,通过打印可以看到其他层目前是能支持的,最后一层有mlu算子完成。
models/yolo.py
diff --git a/models/yolo.py b/models/yolo.py
old mode 100644
new mode 100755
index 5dc8b57..fa0e9fa
--- a/models/yolo.py
+++ b/models/yolo.py
@@ -26,6 +26,8 @@ class Detect(nn.Module):
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
+ self.anchors_list = list(np.array(anchors).flatten())
+ self.num_anchors = len(self.anchors_list)
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
@@ -36,10 +38,32 @@ class Detect(nn.Module):
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
+ #self.tmp_shape=[[1,255,80,64],[1,255,40,32],[1,255,20,16]]
+ self.img_h = 640
+ self.img_w = 640
+ self.conf_thres = 0.25
+ self.iou_thres = 0.45
+ self.maxBoxNum = 1024
+
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
+ output = []
+
self.training |= self.export
+
+ if x[0].device.type == 'mlu':
+ for i in range(self.nl):
+ x[i] = self.m[i](x[i]) # conv
+ y = x[i].sigmoid()
+ # print('y.shape: ',y.shape)
+ output.append(y)
+
+ detect_out = torch.ops.torch_mlu.yolov5_detection_output(output[0], output[1], output[2],
+ self.anchors_list,self.nc, self.num_anchors,
+ self.img_h, self.img_w, self.conf_thres, self.iou_thres, self.maxBoxNum)
+ # [10, 13, 16, 30, 33, 23,30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]
+ return detect_out
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
可以看到,这里将Detect类,修改为,我们mlu支持的算子 torch.ops.torch_mlu.yolov5_detection_output
detect_out = torch.ops.torch_mlu.yolov5_detection_output
这里算子是把img宽高固定为 640 640作为输入。
detect.py需要继续增加逐层运行的方式
增加一个get_boxes的函数,用来从torch.ops.torch_mlu.yolov5_detection_output获取结果后画框,不再依赖cpu的获取框的后处理方式了。
+import numpy as np
+def get_boxes(prediction, batch_size=1, img_size=640):
+ """
+ Returns detections with shape:
+ (x1, y1, x2, y2, object_conf, class_score, class_pred)
+ """
+ reshape_value = torch.reshape(prediction, (-1, 1))
+
+ num_boxes_final = reshape_value[0].item()
+ print('num_boxes_final: ',num_boxes_final)
+ all_list = [[] for _ in range(batch_size)]
+ for i in range(int(num_boxes_final)):
+ batch_idx = int(reshape_value[64 + i * 7 + 0].item())
+ if batch_idx >= 0 and batch_idx < batch_size:
+ bl = reshape_value[64 + i * 7 + 3].item()
+ br = reshape_value[64 + i * 7 + 4].item()
+ bt = reshape_value[64 + i * 7 + 5].item()
+ bb = reshape_value[64 + i * 7 + 6].item()
+
+ if bt - bl > 0 and bb -br > 0:
+ all_list[batch_idx].append(bl)
+ all_list[batch_idx].append(br)
+ all_list[batch_idx].append(bt)
+ all_list[batch_idx].append(bb)
+ all_list[batch_idx].append(reshape_value[64 + i * 7 + 2].item())
+ # all_list[batch_idx].append(reshape_value[64 + i * 7 + 2].item())
+ all_list[batch_idx].append(reshape_value[64 + i * 7 + 1].item())
+
+ output = [np.array(all_list[i]).reshape(-1, 6) for i in range(batch_size)]
+ # outputs = [torch.FloatTensor(all_list[i]).reshape(-1, 6) for i in range(batch_size)]
+ return output
+ # jdict = []
+ # for si, pred in enumerate(output):
+ # box = pred[:, :4] #x1, y1, x2, y2
+ # for di, d in enumerate(pred):
+ # box_temp = []
+ # box_temp.append(np.round(box[di][0], 3).item())
+ # box_temp.append(np.round(box[di][1], 3).item())
+ # box_temp.append(np.round(box[di][2], 3).item())
+ # box_temp.append(np.round(box[di][3], 3).item())
+ # jdict.append({'bbox': box_temp, 'score': (np.round(d[5], 5)).item()})
+ # sorted_jdict = sorted(jdict, key=lambda x:x['score'], reverse=True)
+ # return sorted_jdict
增加 mlu 的配置方式
def detect(save_img=False):
source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
@@ -55,6 +102,27 @@ def detect(save_img=False):
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
+ global quantized_model
+ global quantized_net
+
+ if opt.cfg == 'qua':
+ qconfig = {'iteration':2,'firstconv':False}
+ quantized_model = mlu_quantize.quantize_dynamic_mlu(model, qconfig, dtype='int8', gen_quant=True)
+
+ elif opt.cfg == 'mlu':
+ from models.yolo import Model
+
+ model = Model('./models/yolov5s.yaml').to(torch.device('cpu'))
+ model.float().fuse().eval()
+
+ quantized_net = torch_mlu.core.mlu_quantize.quantize_dynamic_mlu(model)
+
+ state_dict = torch.load("./yolov5s_int8.pt")
+ quantized_net.load_state_dict(state_dict, strict=False)
+
+ quantized_net.eval()
+ quantized_net.to(ct.mlu_device())
+
# Run inference
增加mlu的推理方式
img = torch.zeros((1, 3, imgsz, imgsz), device=device) # init img
@@ -68,8 +136,37 @@ def detect(save_img=False):
# Inference
t1 = time_synchronized()
- pred = model(img, augment=opt.augment)[0]
+
+
+ if opt.cfg == 'qua':
+ pred = quantized_model(img)[0]
+ torch.save(quantized_model.state_dict(), 'yolov5s_int8.pt')
+ print('run qua')
+
+ elif opt.cfg == 'mlu':
+ img = img.type(torch.HalfTensor).to(ct.mlu_device())
+ img = img.to(ct.mlu_device())
+ pred = quantized_net(img)[0]
+
+ pred=pred.data.cpu().type(torch.FloatTensor)
+ box_result = get_boxes(pred)
+ print("im0s.shape:",im0s.shape)
+ print(box_result)
+ res = box_result[0].tolist()
+
+ with open("yolov5s_mlu_output.txt","w+") as f:
+ for pt in sorted(res, key=lambda x:(x[0],x[1])):
+ f.write("{}\n{}\n{}\n{}\n".format(pt[0],pt[1],pt[2],pt[3]))
+ cv2.rectangle(im0s, (int(pt[0]), int(pt[1])), (int(pt[2]), int(pt[3])), (255,0,0), 2)
+ cv2.imwrite("mlu_out_{}.jpg".format(os.path.basename(path).split('.')[0]), im0s)
+ print('run mlu')
+ elif opt.cfg == 'cpu':
+ pred = model(img, augment=opt.augment)[0]
+ print('run cpu')
+
+ if opt.cfg != 'cpu':
+ continue
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
运行
python detect.py --device cpu --weights yolov5s-v4.pt --cfg mlu
结果:
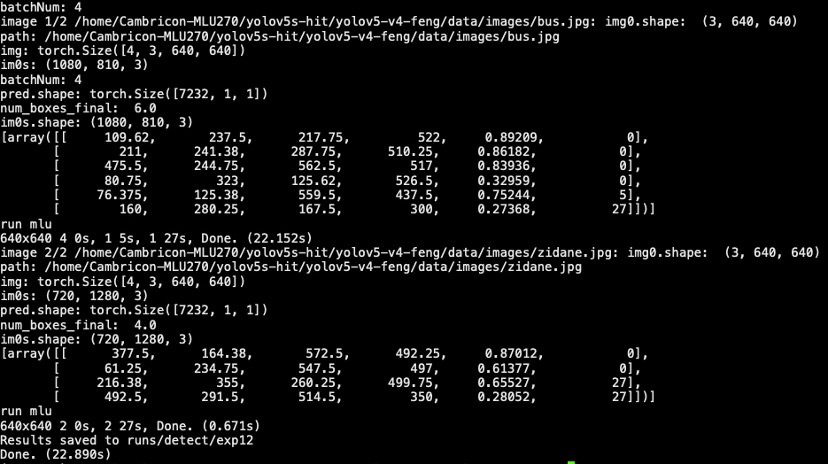
这里是对测试图的结果:

融合
增加部分代码,如下的opt.jit部分
+ elif opt.cfg == 'mlu':
+ from models.yolo import Model
+
+ model = Model('./models/yolov5s.yaml').to(torch.device('cpu'))
+ model.float().fuse().eval()
+
+ quantized_net = torch_mlu.core.mlu_quantize.quantize_dynamic_mlu(model)
+
+ state_dict = torch.load("./yolov5s_int8.pt")
+ quantized_net.load_state_dict(state_dict, strict=False)
+
+ quantized_net.eval()
+ quantized_net.to(ct.mlu_device())
+
+ if opt.jit:
+ print("### jit")
+ ct.save_as_cambricon('yolov5s_int8_1_4')
+ torch.set_grad_enabled(False)
+ ct.set_core_number(4)
+ trace_input = torch.randn(1, 3, 640, 640, dtype=torch.float)
+ input_mlu_data = trace_input.type(torch.HalfTensor).to(ct.mlu_device())
+ quantized_net = torch.jit.trace(quan
测试
python detect.py --weights yolov5s-v4.ptt --cfg mlu --jit True
最后得到 yolov5s_int8_1_4.cambricon 离线模型
其他

