

一、大算子的原理
对于Yolov3模型我们可以简单的将模型分为特征提取部分和处理识别框的后处理部分。
很多框架的常见Yolov3后处理实现方案中往往都采用了比较高层的实现方式。反映到底层原理上,往往会出现大量小算子拼接的情况。这使得我们可以通过底层算子融合优化的方式进一步提升现有实现的性能。这种将多个算子在底层融合实现的优化方式我们形象的称之为“大算子”。
二、Yolov3DetectionOutput在模型上的使用
首先为了使用大算子我们需要在模型层面上进行修改,将原有的一系列后处理算子替换为大算子。
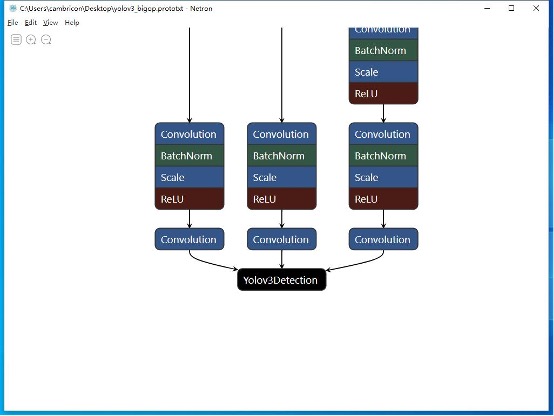
更详细的关于算子与框架和模型如何结合工作的内容请参考【Caffe Yolov3 移植教程】。
三、CNPlugin
CNPlugin是寒武纪推出的BANG C算子集合,主要基于CNML提供的函数接口方便用户将BANG C写成的MLU算子与CNML和框架结合运行调用,从而实现模型推理需求的可定制化和高效运行。
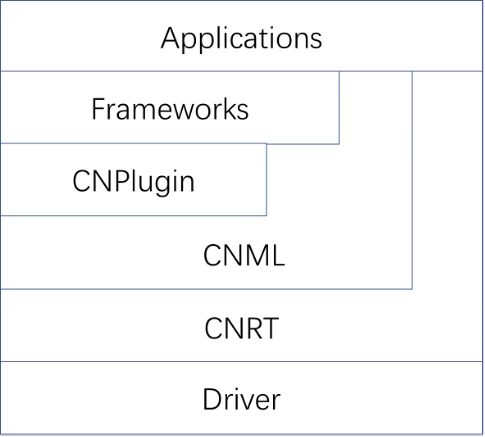
CNPlugin的每个算子都包含Host端和MLU端两部份代码。Host端代码的主要形式是通过CNML的PluginOp相关API实现对BANG C kernel的封装以达到方便框架调用和复用的目的。
Yolov3DetectionOutput 也被包含在了CNPlugin算子集中。Yolov3DetectionOutput的Host端主要代码如下所示:
参数标记:
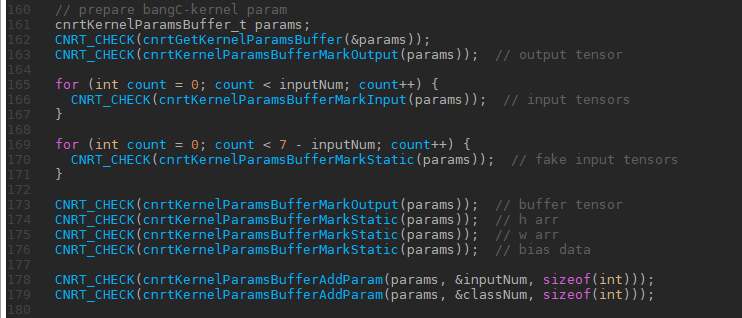
这里调用了一系列ParamsBuffer的API实现了host端向MLU端的函数参数传递。特别值得注意的是,为了方便底层CNML实现算子之间的图构建等操作,在创建Plugin算子时需要对输入,输出,常量tensor分别进行标注。标注的调用顺序必须和BANG C Kernel的传参顺序一致。
在使用invoke方式运行BANG C Kernel时不需要这些标注。
这系列接口的详细使用方法建议参考《寒武纪CNRT用户手册》和《寒武纪CNRT开发者手册》。
创建PluginOp:
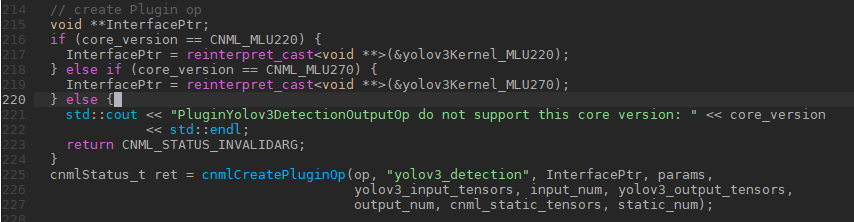
为了保证MLU220和MLU270的代码复用,这里需要根据core version选择相应的函数指针。
这里变量 op是算子创建的结果,创建算子的相关信息会保存在op这个结构体中方便后面的运行调用。

Forward过程非常简单,使用上面创建好的op直接调用cnmlComputePluginOpForward_V3即可。
详细代码请参考:
Cambricon-CNPlugin-MLU270/pluginops/PluginYolov3DetectionOutputOp/plugin_yolov3_detection_output_op.cc
四、Yolov3DetectionOutput后处理算法解析
为了方便大家理解后续的BANG C代码,这里我们先结合CPU版本的实现解释一下Yolov3DetectionOutput的算法和实现方式。
cnmlCpuComputePluginYolov3DetectionOutputOpForward是后处理的CPU实现。
输入Inputs的数据格式是:
[input_num, batch_size, anchorNum, 5 + classnum, inputH * inputW]
整体上说,后处理的CPU实现分为三部分:1、框信息的预处理,类似一个decode过程。2、NMS过程,实现框的选择和合并。3、框排序,当选出的结果框数量大于maxBoxNum时选取score最大的maxBoxNum个。
对于第一个decode部分,只要对照上面的数据格式就非常很容易理解这里非常复杂的数组偏移计算。通过batch, inputNum, anchorNum, inputH * inputW四重循环将input中每个框和概率的数据转换成obj_kept, loc_kept, prob_kept三个数组的表示方法,分别表示objectness,框的位置和框中内容在所有类别上的概率分布。在这个过程中,所有objectness小于confidence_thresh的框都会被过滤掉。
第二部分,NMS过程是后处理的重点。基本原理是针对每一个类,每次循环选取这个类中概率最高的框与其他所有框计算IOU。如果某个框与最大概率框的IOU大于nms_thresh。这个框对应的概率被设为-1,表示被过滤掉了。这一步的计算结果存在temp_outputs数组中。

第三部分topk的实现非常简单。通过双重循环选取temp_outputs中概率最大的maxBoxNum个框放入outputs中。
以上就完成了一个CPU端完整的NMS计算过程。
五、Yolov3DetectionOutput代码解析
在本算子中值得注意的一些BANG C 实现技巧和优化手段有:
- 充分使用向量化操作并由此带来的对齐等要求。
- 针对问题算法特点设计的多核拆分方法。
- 针对不同问题规模分别制定的数据拆分和数据调度策略,以及不同策略之间的代码复用。
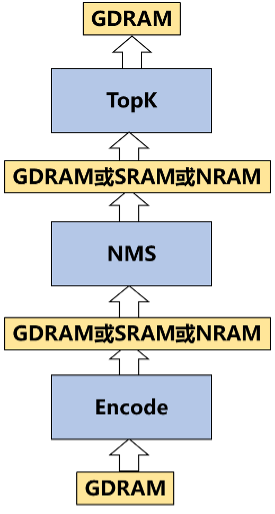
整体算法上BANG C的后处理算子使用了和CPU程序类似的结构,也分为三个部分,Preprocess部分,NMS部分和TopK部分。在每个部分我们都要考虑模块之间的衔接问题,每个模块的计算结果存到哪里,下一步计算又从哪里取得输入数据。其中NRAM速度最快但是空间也最小,SRAM速度其次空间也其次,GDRAM速度最慢空间也最大。所以根据不同的问题规模高效选择计算过程中间结果的存储位置可以大大加快程序的计算效率。
其中问题规模最小的情况下可以选择利用NRAM作为中间结果的暂存位置。随着问题规模的扩大选择SRAM或GDRAM存储结果。
除了问题规模之外,中间结果的暂存位置还和多核计算的策略有关。在实际开发中,为了简化程序开发的难度,我们一般建议算子只要考虑单Core(Block),单Cluster(4核,UNION1),四Cluster(16核,UNION4)即可。
其中Block的情况下不支持SRAM的使用。
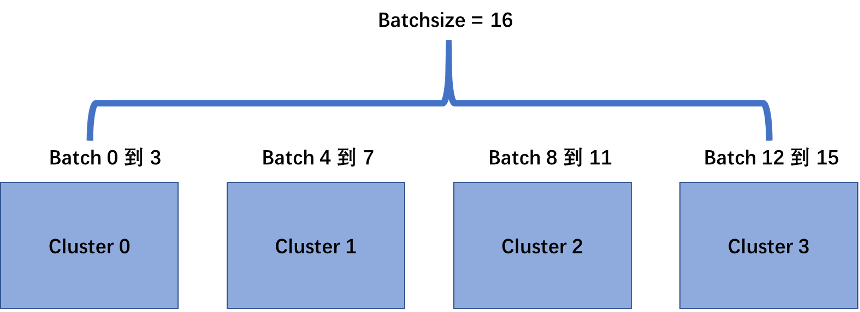
多核拆分的计算策略需要从具体算法的结构出发进行设计。对于人工智能问题,大多数算子都可以对batchsize进行拆分。对于本算子,大的结构上我们也使用这种拆分方法。对于Batchsize = n的情况,我们将n个数据尽量平均的分配到每个Cluster上去。每个Cluster每次只处理一个batch。
算法yolov3Kernel的inputs输入数据排列为:[batchsize, input_num, inputH, inputW, num_mask_groups * (5 + classnum)]
以下我们针对这三部分分别解释具体的实现原理。
1)第一部分:Preprocess部分
此部分是完成一个数据转换的过程,对于某个框来说,计算过程比较简单,主要注意数据对齐即可。比较复杂的部分依旧是数据的拆分策略。由于多数时候数据规模限制不能一次性的调度所有数据到NRAM上,所以必须根据数据和算法本身的特点对数据进行切分,对NRAM达到分时复用的效果。
观察Preprocess要处理的数据特点,我们选择在inputH或者inputW上进行数据切分。
对于W足够小的情况就只拆分H,否则就需要同时拆分H和W。
判断拆分的依据是:
int limit = (NRAM_BUFFER_SIZE / sizeof(T) / 2 / (2 + entryPad) - 64) / w;
这里64是为了保留一小块空间作为其余的NRAM变量使用。除以2是因为计算过程中需要一份额外的临时空间。
只要limit > 0那么每次我们就可以处理limit份数据。
在完成拆分之后会出现两种情况。第一种情况下只拆分H每次处理limit * w的数据。另一种情况下拆分H和W,每次处理limit = (NRAM_BUFFER_SIZE / sizeof(T) / 2 / (2 + entryPad) - 64);的数据。
在完成数据的拆分后程序会调用DecodeAllBBoxesFullW或DecodeAllBBoxesPartW来Decode选取的数据。这两个函数大同小异,我们就以DecodeAllBBoxesFullW为例来解释这里用到的编程技巧。
DecodeAllBBoxesFullW主要部分的向量计算过程比较容易理解。比较值得一提的编程技巧有两个。
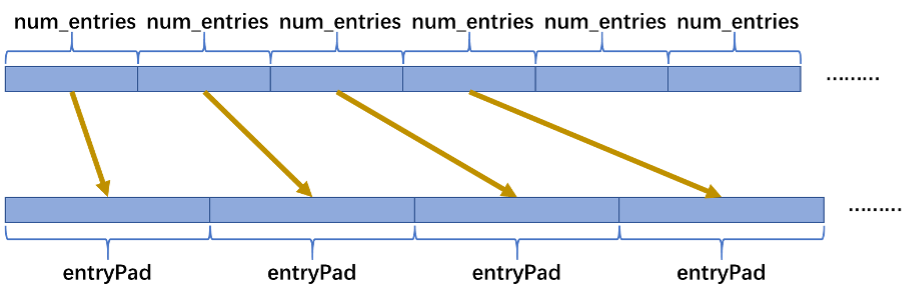
第一个技巧是使用memcpy的数据对齐。由于原有数据的num_entries在gdram是没有对齐到64并且是连续存放的。所以在开始计算之前我们需要将数据在NRAM上对齐到64存放。这里使用带步长的memcpy是一种比较高效的转换方式。
第二个比较重要的技巧在于原有的数据排列方式不适合用于向量化的操作。为此我们需要对数据排列做 __bang_transpose 操作。
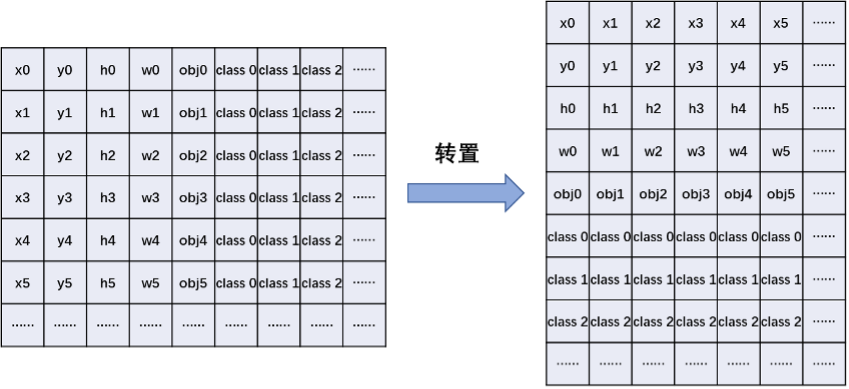
转置之后就非常便于对每一类数据做相应的向量操作了。
最后一步在完成主要的decode计算之后就可以使用__bang_cycle_gt和__bang_collect来实现将所有conf小于confidence_thresh的框过滤掉的效果。
Preprocess的多核过程由于将结果存回了SRAM或者GDRAM,然后下一个阶段的NMS过程会直接从SRAM或者GDRAM取数据,所以绝大多数处理过的框数据是不需要同步的。但是由于我们在前面使用confidence_thresh滤掉了一部分框数据。所以剩下的框的数量需要进行Cluster内部的数据同步。这里我们使用sync和SRAM的读写来完成这种多核同步。
2)第二部分:NMS
同样根据问题规模分为两种情况,一种是将SRAM作为buffer的情况,另一种是GDRAM作为buffer的情况。在拆分策略上,我们观察算法可以发现由于在class之间NMS过程是相互独立的,所以我们可以选择以class为算法拆分的依据。
由此,NMS的第一步就是将所有的框数据载入NRAM。然后通过class的循环载入本次要处理的几个class数据到NRAM。
在nms_detection函数的部分,nms_detection本身比较复杂,充分的考虑了多种情况。但在目前的情况下我们可以只考虑NRAM足够大,可以放下完整的一个class的情况。对应到代码中,就是MODE==1 且 src == NRAM且core_limit==1的情况。

在这种情况下,只要一个MLU core就可以完成某一class的全部NMS操作,免去了核间同步等操作。是一种比较高效也容易理解的情况。
在nms_detection的主体部分是keep次的循环。每次循环寻找概率最大的框然后将这个框与其他所有框求IOU并过滤IOU大于阈值的框。
for (int keep = 0; keep < keepNum; keep++) {
找最大的框;
将最大的框保存到SRAM或者GDRAM中;
计算最大框与其余框的IOU并丢弃一部分小于阈值的框。
}
总的来说这三步过程在目前面对的情况下比较容易理解。值得注意的是在计算过程中,为了节省NRAM的使用变量空间做了大量的复用操作。
3)第三部分:TopK部分
对于detection算子的最后一个部分,TopK部分,我们不再考虑复杂的多核拆分问题。为了避免多核同步的开销,我们只用一个MLU core来完成所有任务。如果最后保留下的框数量大于num_max_boxes,则循环num_max_boxes次取最大并完成在输出GDRAM上的数据摆放。而如果最后保留下的框数量小于num_max_boxes则直接使用__bang_transpose来完成框的摆放和GDRAM写回。