

模型训练:BERT的SQuAD任务
一、内容和目标
1. 实验内容
本实验主要介绍基于寒武纪 MLU370 (简称 MLU ) AI 处理器与寒武纪 PyTorch 框架的 BERT(基于 Transformers v4.0.1)训练方法。在官方源码的基础上,进行简单移植和修改,使用MLU370 加速训练 BERT 算法模型,并介绍基于 MLU370 的混合精度训练方法。后续章节将会详细介绍移植过程。
2. 实验目标
- 掌握使用寒武纪 MLU370 和 PyTorch 框架进行混合精度训练的基本方法。
- 理解 BERT 模型的整体网络结构及其适配流程。
二、前置知识
1. 寒武纪软硬件平台介绍
-
硬件:寒武纪 MLU370 AI 加速卡
-
框架:PyTorch 1.6
2. 寒武纪 PyTorch 框架
为⽀持寒武纪 MLU 加速卡,寒武纪定制了开源⼈⼯智能编程框架PyTorch(以下简称 Cambricon PyTorch)。
Cambricon PyTorch 借助 PyTorch ⾃⾝提供的设备扩展接⼝将 MLU 后端库中所包含的算⼦操作动态注册到 PyTorch 中,MLU 后端库可处理 MLU 上的张量和 AI 算⼦的运算。Cambricon PyTorch 会基于 CNNL 库在 MLU 后端实现⼀些常⽤AI 算⼦,并完成⼀些数据拷⻉。
Cambricon PyTorch 兼容原⽣ PyTorch 的 Python 编程接⼝和原⽣ PyTorch ⽹络模型,⽀持以在线逐层⽅式进⾏训练和推理。⽹络可以从模型⽂件中读取,对于训练任务,⽀持 float32,float16等混合精度。获取更多有关Cambricon PyTorch资料,请参考寒武纪官网文档PyTorch相关内容。
三、网络结构
BERT 的全称为 Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型, BERT 的每一层由一个Encoder 单元构成。根据 Encoder 集成多少分为两种:
-
在比较大的BERT模型中,即BERT_large,有24层Encoder,每层中有16个Attention,词向量的维度是1024。
-
在比较小的BERT模型中,即BERT_base,有12层Encoder,每层有12个Attention,词向量维度是768。
BERT可以有效改进许多自然语言处理任务,包括自然语言分类,文本匹配,命名实体识别和SQuAD 问答等任务。本文主要介绍基于 BERT_base 的 SQuAD 问答任务,以下是其训练框架结构:
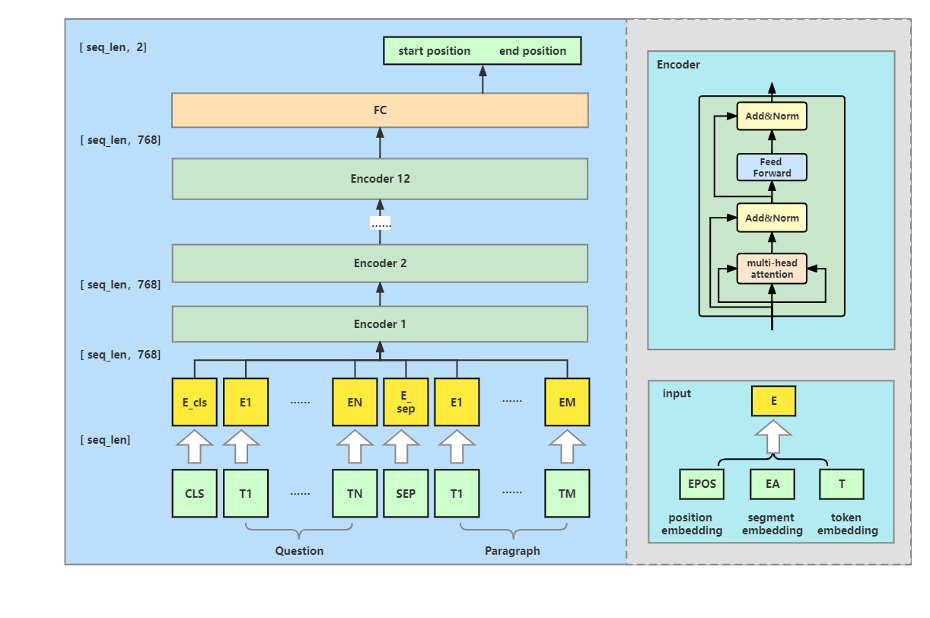
其中:
-
input 表示输入 Encoder之前的各embedding融合,包含position embedding,segment embedding和token embedding。
-
Encoder 是Transformer的Encoder部分,每个Encoder单元由一个multi-head-Attention + Layer Normalization + feedforword + Layer Normalization 叠加产生。
四、模型训练
下图为模型训练的四个步骤:

1.【工程准备】:安装依赖环境,下载源码、数据集和模型等
2.【移植修改】:为便于用户移植和修改,本次实验通过patch方式将适配后的训练代码应用于源码,使得能够在寒武纪 MLU 上实现训练
3.【训练】:本文提供了2种训练方式:
-
From pretrained training:基于预训练模型进行训练
-
Resume Training:在上次训练基础上继续训练
4.【精度验证】:提供脚本测试训练的精度
五、相关链接
实验代码仓库:https://gitee.com/cambricon/practices
Modelzoo仓库:https://gitee.com/cambricon/modelzoo