

模型推理: Tacotron2语音合成
一、内容和目标
1. 实验内容
-
本实验主要介绍基于寒武纪 MLU370 硬件平台及寒武纪 PyTorch 框架的 Tacotron2 语音合成推理应用的开发方法。
-
基于 Tacotron2 语音合成应用和寒武纪 MLU370 硬件平台,以文本作为输入,合成类人的语音输出。
2. 实验目标
-
掌握使用寒武纪 MLU370 硬件平台及寒武纪 PyTorch 框架进行 AI 模型移植与推理的基本方法。
-
理解 Tacotron2 模型和 WaveGlow 模型的网络结构。
二、平台介绍
寒武纪软硬件平台介绍
-
硬件:寒武纪 MLU370 AI 加速卡
-
框架:Pytorch 1.6
-
系统环境:寒武纪云平台
三、网络结构
Tacotron2 是一个可直接从文本合成语音的端到端语音合成 AI Network 架构,合成的语音可与真人语音媲美。
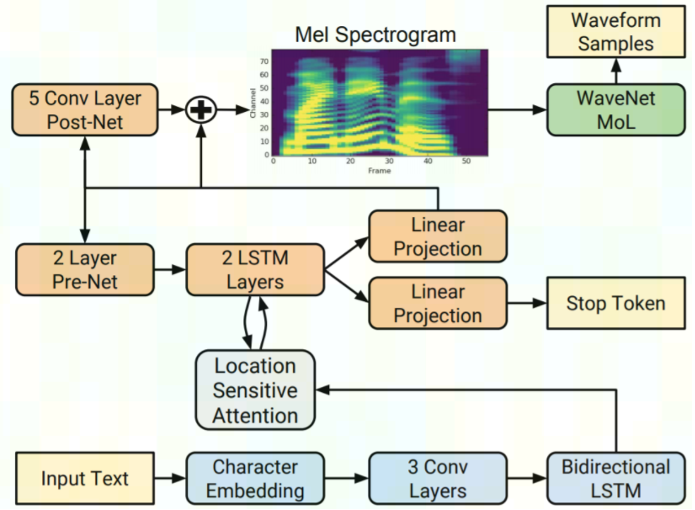
Tacotron2 系统由两部分构成,第一部分是循环 seq2seq 结构的特征预测网络,负责把字符向量映射为梅尔声谱图,第一部分后再接一个 WaveNet 模型的修订版,即 WaveGlow,负责把梅尔声谱图合成为时域波形。编码器(下图中的蓝色块)将整个文本转换为固定大小的隐藏特征表示。然后,自回归解码器(橙色方块)使用该特征表示,每次生成一个频谱图帧。在 Tacotron2 中,使用基于流生成的 WaveGlow 代替了自回归 WaveNet(绿色方块)。
从 [Tacotron2论文] 可知,Tacotron2 网络的结构如下图所示:
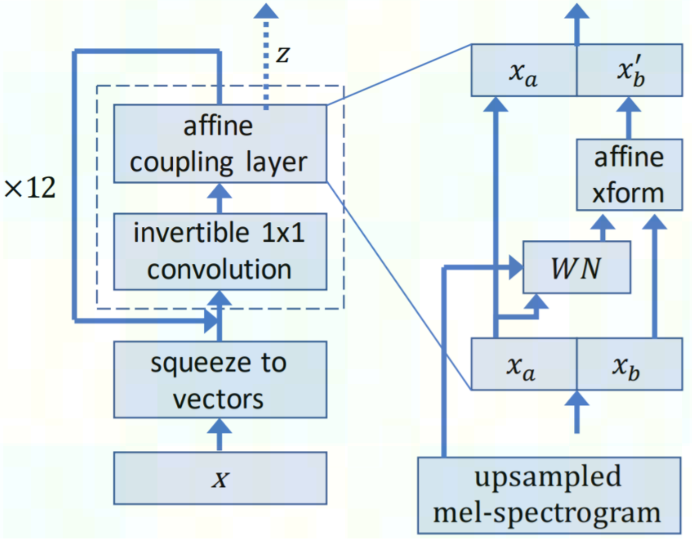
从 [WaveGlow 论文] 可知,WaveGlow 网络的结构如下图所示。WaveGlow 模型是一种基于流的生成模型,它从以梅尔谱图为限制条件的高斯分布中生成音频样本。在训练期间,模型学习如何通过一系列 Flow 将数据集分布变换为球形高斯分布。前述 Flow 中的一个步骤包括可逆卷积,然后是作为仿射耦合层的修改过的 WaveNet。在推理过程中,网络被反转,音频样本从高斯分布中生成。
四、推理应用
本实验按照下述流程进行展开:
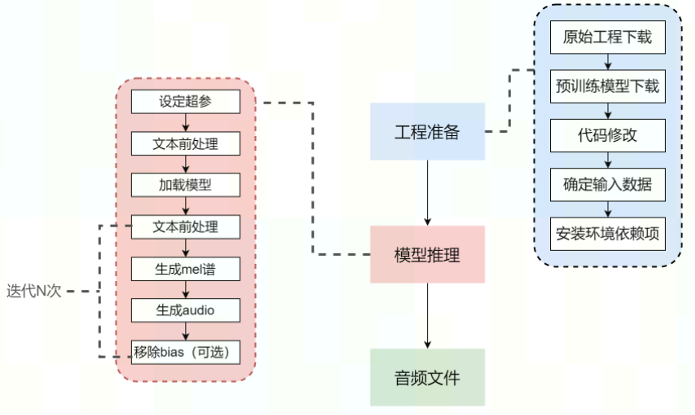
编写推理应用包含两个步骤:工程准备和模型推理。
STEP 1. 工程准备
-
原始环境准备:下载源码和预训练模型。
-
代码修改:原始工程代码并不能直接在寒武纪 PyTorch 内运行,还需进行适当修改:比如:修改本地路径,设计MLU相关库和函数的导入和使用等。
-
确定待合成的文本:待合成为语音的文本在
src/test_infer.py内的main()中,可根据自己需求对main()中的texts进行修改 -
安装环境依赖项:默认此时已经入
`Cambricon PyTorch`虚拟环境。按照txt安装环境依赖。
STEP 2. 模型推理
-
设定超参:正式开始推理之前,我们需要设定相关参数的值,如预训练模型路径、推理设备、输入文本长度等。
-
文本前处理:在前处理阶段,Tacotron2 会基于`texts`生成数字序列(
sequences_padded)。 -
加载模型:根据传入的命令行参数加载模型,并将模型拷贝至 MLU 上。
-
文本特征序列生成 mel 谱:在对输入文本完成前处理得到文本序列特征
`sequences_padded`后,即可开始基于`sequences_padded`生成 mel 谱。 -
基于 WaveGlow 从 mel 谱生成 audio:得到 mel 谱后,利用 WaveGlow 生成 audio 数据,并将 audio 数据保存到本地。在本实验中,将直接展示合成的 audio 音频,运行下方代码块后,即可得到支持在线播放的 audio 音频。
-
移除 WaveGlow 的 bias(可选):移除 WaveGlow 的 bias 后可能可以得到更加清晰的音质。
五、相关链接
实验代码仓库:https://gitee.com/cambricon/practices
Modelzoo仓库:https://gitee.com/cambricon/modelzoo