

模型推理: OCR 实现
一、内容和目标
1. 实验内容
-
本实验主要介绍飞桨(paddlepaddle)框架的开发套件 PaddleOCR,OCR模型(dbnet+crnn)迁移至寒武纪MLU370 MagicMind 平台的过程。
-
基于 OCR (Optical Character Recognition, 光学字符识别) 的 (dbnet + crnn)网络和寒武纪MLU370 MagicMind 平台,您可以读取本地图像数据作为输入,对图像中的文字位置进行检测,并进行文字信息提取。
2. 实验目标
-
完成PaddleOCR模型转换。
-
掌握使用寒武纪 MLU370 MagicMind 平台进行AI模型推理的基本方法。
-
理解 dbnet + crnn 模型的整体网络结构及其开发调试细节。
二、前置知识
1. 寒武纪软硬件平台介绍
-
硬件:寒武纪 MLU370 AI 加速卡
-
框架:PyTorch 1.6、MagicMind 0.14.0
2. PaddlePaddle 介绍
飞桨(PaddlePaddle)以百度多年的AI技术研究和业务应用为基础,集AI核心训练和推理框架、基础模型库、端到端开发套件、丰富工具组件于一体。
3. MagicMind 介绍
MagicMind 是⾯向寒武纪 MLU370 (寒武纪处理器,简称MLU) 的推理加速引擎。 MagicMind 能将人工智能框架(TensorFlow,PyTorch 等)训练好的算法模型转换成 MagicMind 统⼀计算图表⽰,并提供端到端的模型优化、代码⽣成以及推理业务部署能⼒。用户无需过多关注底层硬件细节,只需专注于推理业务开发。
获取更多有关 MagicMind 资料,请参考 寒武纪官网文档 相关内容。
三、原始模型
OCR (Optical Character Recognition, 光学字符识别) 是指对图像进行分析识别处理,获取文字和版面信息的过程,是典型的计算机视觉任务。
OCR 系统的 pipeline 如下:
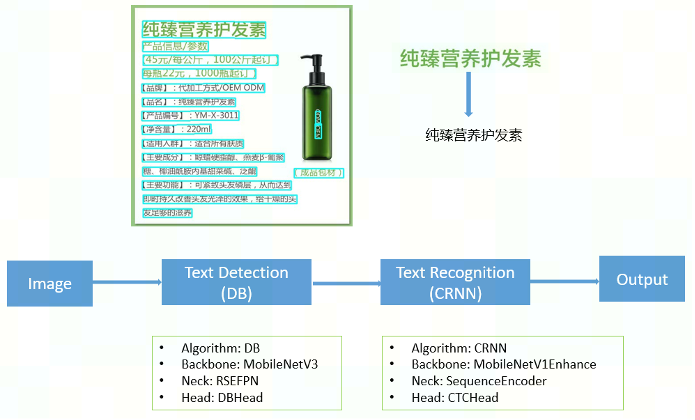
1. 文本检测
文本检测任务:输入给定的图像,找出文本的区域。
DBNet 是一个基于分割的文本检测算法,该算法提出了可微分阈值 Differenttiable Binarization module (DB moudle) ,使用动态阈值来区分文本区域和背景。
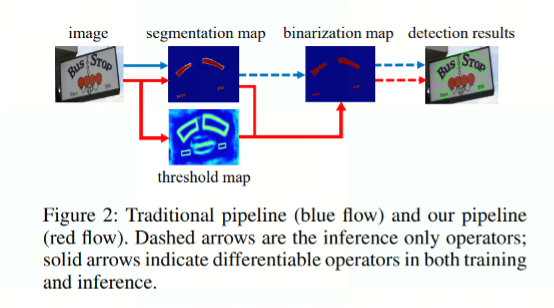
* 上图来自论文[Real-time Scene Text Detection with Differentiable Binarization]
-
蓝色箭头描述的是基于分割的普通文本检测算法流程,该方法得到分割结果后采用一个固定的阈值得到二值化分割图,最后使用一个像素聚类操作得到文本区域。
-
红色箭头描述的是DBNet算法流程,不同点在于DBNet 有个阈值图,通过网络去预测图片每个位置处的阈值,而不是使用一个固定的值,能更好的分离文本背景和前景。
DBNet 网络结构:
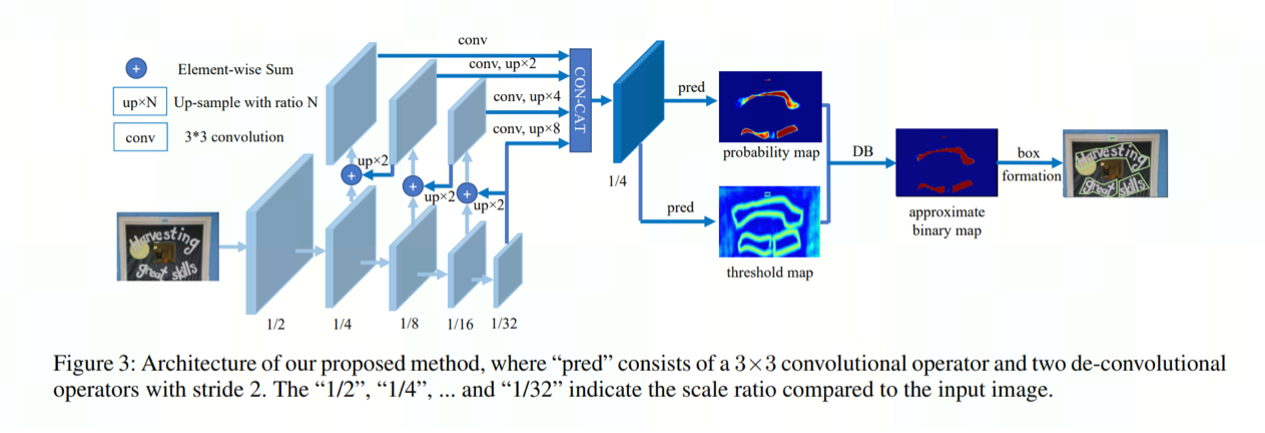
* 图片来自论文[Real-time Scene Text Detection with Differentiable Binarization]
-
Backbone网络:负责提取图像的特征。
-
RSEFPN网络:引入残差结构和通道注意力机制,提升特征图的表征能力。
-
Head网络:计算文本区域概率图。
2. CRNN-文本识别
文本识别任务:对检测框进行文本识别,从而得到文本框的文字内容。
CRNN是基于CTC 算法,CRNN 主要用于解决而规则文本,基于CTC 算法可以有较快的预测速度并且很好的适用于长文本。
CRNN 网络结构:
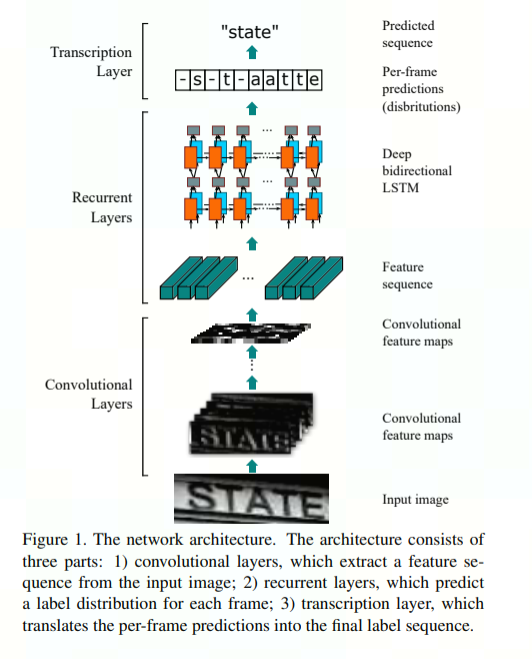
* 图片来自论文[An End-to-End Trainable AI Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition]
-
Backbone网络:负责提取图像的特征。
-
RSEFPN网络:引入残差结构和通道注意力机制,提升特征图的表针能力。
-
Head网络:计算文本区域概率图。
四、模型推理
模型推理整体流程如下图所示,主要包含模型工程准备,模型生成和模型推理三部分。
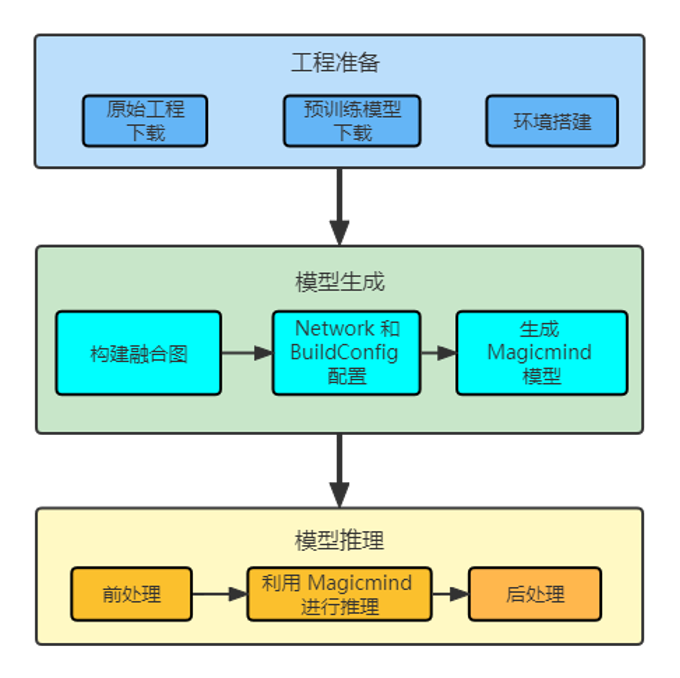
STEP 1. 工程准备
-
原生工程下载:下载原始 PaddleOCR2Pytorch 工程,本实验已经提供工程环境,PaddleOCR2Pytorch源代码在
src/PaddleOCR2Pytorch/目录下。 -
搭建环境:安装本实验所需的额外环境,
pip install –r requirement.txt。 -
预训练模型下载:下载 OCR 预训练模型,并将其放置于
ocr_model目录下,本实验的sh已自动操作。
STEP 2. 模型生成
-
PaddleOCR 训练模型转 PyTorch 模型,本实验的sh 已自动操作。
-
构建融合图:MagicMind 目前只支持,使用 jit.trace 工具把网络编译为一张融合图,并保存,方便 MagicMind 后期parser 操作。
-
Network 和 BuildConfig 配置: MagicMind ⽀持直接导⼊框架训练好的模型,并表⽰成 Network 对象。模型导⼊⼯作由 Parser 来完成。MagicMind 还提供了BuilderConfig 来配置 Builder 的行为,通过 BuilderConfig 设置,用户可配置硬件平台,输入摆数,归一化参数等信息。
-
配置量化数据校准器:MagicMind 提供了量化较准器(Calibrator),它支持 post-training 量化功能,能够基于浮点模型和样本数据计算并设置数据的分布范围,并且可以根据数据分布的特点,选择不同的量化粒度。
-
生成 MagicMind 模型:调用 MagicMind 的
build_model接口生成模型,build_model⽣成的模型中包含MLU指令、图结构等静态数据。⽣成的模型可以序列化到⽂件或内存,或从⽂件或内存反序列化,从⽽满⾜跨平台部署需求。
STEP 3. 模型推理
1. 前处理:
-
DBNet 的前处理主要为归一化处理,以及对图片的尺寸进行限制。
-
CRNN 的前处理主要为,对输入网络的图片数据进行缩放到统一尺寸(3,48,320),并且完成归一化处理。
2. 利用 MagicMind 进行推理:
3. 后处理:
-
DBNet 后处理根据概率图中文本区域的响应计算出文本框坐标。
-
CRNN 后处理主要是将识别网络返回的各个时间步上的最大索引值,解码成对应文字结果。
五、相关链接
实验代码仓库:https://gitee.com/cambricon/practices
Modelzoo仓库:https://gitee.com/cambricon/modelzoo