

一、内容和目标
1. 实验内容
- 本实验主要介绍基于寒武纪 MLU370 MagicMind 平台的 Conformer (ONNX, Python, float32) 语音识别推理应用的开发方法。
2. 实验目标
-
掌握使用寒武纪 MLU370 MagicMind 平台进行 AI 推理的基本方法。。
-
理解 Conformer 模型的整体网络结构及其开发调试细节。
-
使用 MagicMind PluginOp 加速 AI Network。
二、前置知识
1. 寒武纪软硬件平台介绍
-
硬件:寒武纪 MLU370 AI 加速卡
-
框架:ONNX、MagicMind 0.14.0
2. MagicMind 介绍
MagicMind 是⾯向寒武纪 MLU370 (寒武纪处理器,简称MLU) 的推理加速引擎。 MagicMind 能将人工智能框架(TensorFlow,PyTorch 等)训练好的算法模型转换成 MagicMind 统⼀计算图表⽰,并提供端到端的模型优化、代码生成以及推理业务部署能⼒。用户无需过多关注底层硬件细节,只需专注于推理业务开发。
获取更多有关 MagicMind 资料,请参考 寒武纪官网文档 相关内容。
3. PluginOp 介绍
用户自定义算子称为 Plugin 算子,由应用程序实现和实例化,生存期必须覆盖 MagicMind 引擎的生命周期。
三、网络结构
针对Conformer 是 Google 在 2020 年提出的语音识别模型,主要结合了 CNN 和 Transformer 的优点,其中 CNN 能高效获取局部特征,而 Transformer 在提取长序列依赖的时候更有效。 Conformer 则是将卷积应用于 Transformer 的 Encoder 层,用卷积加强Transformer 在 ASR 领域的效果。
论文链接:【Conformer: Convolution-augmented Transformer for Speech Recognition】
Conformer Encoder 的总体架构如图所示。其中 Conformer Block 是由 Feed Forward Module,Multi-Head Self-Attention Module, Convolution Module 三个子 Module 组成。
其网络具体构造方式为由两个 Feed Forward Module 夹着一个 Multi-Head Self-Attention Module 和一个 Convolution Module 的类三明治结构,每个模块都有各自的残差模块,其中 Feed Forward Module 中残差系数设为 1/2。

* 图片来自论文 [Conformer: Convolution-augmented Transformer for Speech Recognition]
四、模型推理
模型推理整体流程如下图所示,主要包含模型工程准备,模型生成和模型推理三部分本实验使用寒武纪推理引擎 MagicMind 搭建了简单的推理应用,主要包括 Encoder 和 Decoder 两部分。
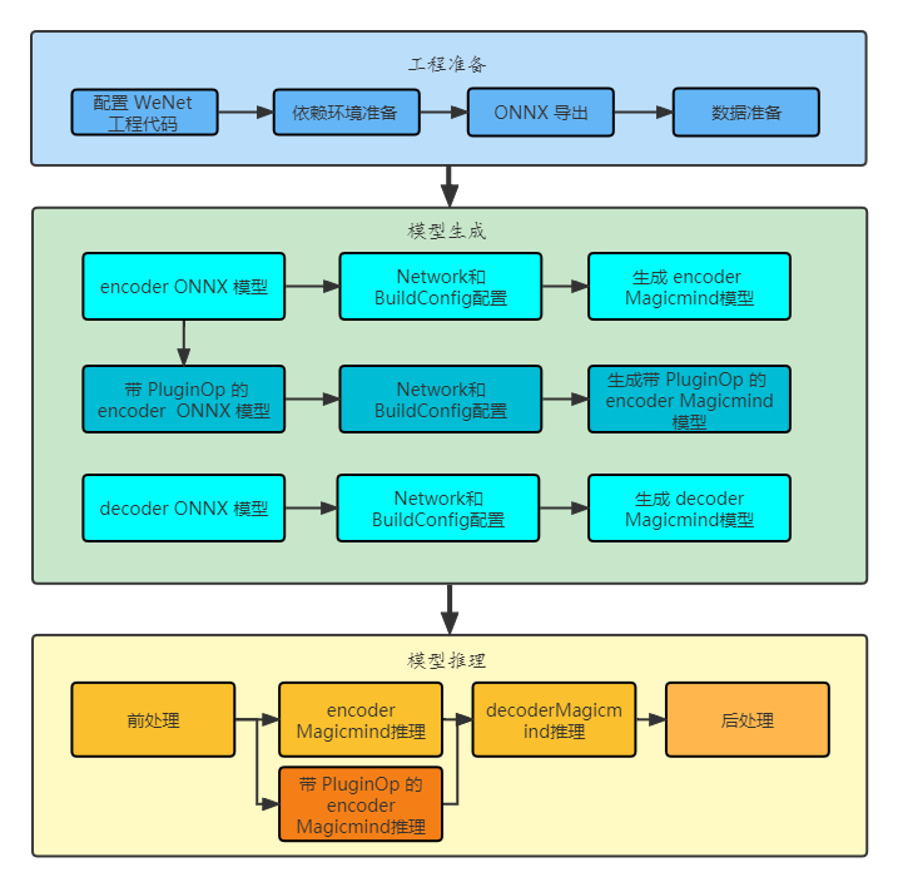
这里沿用了官方的前后处理以及公开的预训练模型,主要移植了和寒武纪推理引擎相关的部分。
STEP 1. 工程准备
-
原生工程下载:下载原始 WeNet 工程,本实验已经提供工程环境,WeNet 源代码在
wenet_export_onnx目录下。 -
预训练模型下载:下载 WeNet 预训练模型,并将其放置于model目录下,本实验的sh已自动操作。
-
搭建环境:安装本实验所需的额外环境。
pip install torch==1.9.1
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install onnx_graphsurgeon --index-url https://pypi.ngc.nvidia.com
bash install_ctc_decoder.sh
STEP 2. 模型生成
-
构建融合图:用 PyTorch 框架导出 ONNX,方便 MagicMind 后期 parser 操作,本实验的sh 已自动操作。
-
Network 和 BuildConfig 配置: MagicMind ⽀持直接导入框架训练好的模型,并表⽰成 Network 对象。模型导入工作由 Parser 来完成。MagicMind 还提供了BuilderConfig 来配置 Builder 的行为,通过 BuilderConfig 设置,用户可配置硬件平台,输入摆数,归一化参数等信息。
-
生成 MagicMind 模型:调用 MagicMind 的
build_model接口生成模型,build_model生成的模型中包含MLU指令、图结构等静态数据。生成的模型可以序列化到文件或内存,或从文件或内存反序列化,从而满足跨平台部署需求。
STEP 3. 模型推理
-
前处理:读取文件列表,把语音音频解析成模型输入。
-
利用 MagicMind 进行推理:

3. 使用 PluginOp 加速:上述推理过程可以使用 PluginOp 进行加速。
4. 后处理:MagicMind 处理完后,将结果按字典映射回文字。
五、相关链接
实验代码仓库:https://gitee.com/cambricon/practices
Modelzoo仓库:https://gitee.com/cambricon/modelzoo