

一、内容和目标
1. 实验内容
本实验主要介绍基于寒武纪 MLU370 (寒武纪处理器,简称MLU)与寒武纪 PaddlePaddle 框架的DBNet 文本检测训练方法。开发者可在PaddleOCR 套件下通过工具脚本 + 配置文件的方式来执行文本检测任务。
2. 实验目标
-
掌握使用寒武纪 MLU370 和 PaddleOCR 套件进行模型训练的基本方法。
-
理解 DBNet 模型的整体网络结构及其适配流程。
二、前置知识
1. 寒武纪软硬件平台介绍
-
硬件:寒武纪 MLU370 AI 加速卡
-
模型套件:PaddleOCR
2. 寒武纪 PaddlePaddle 框架
寒武纪 MLU370 系列是一款专门用于 AI 的加速卡。Cambricon PaddlePaddle 当前可以支持在寒武纪 MLU370 系列板卡上进行模型训练。Cambricon PaddlePaddle 借助 PaddlePaddle 自身提供的设备扩展接口将 MLU 后端库中所包含的算子操作动态注册到PaddlePaddle 中,MLU 的后端库可处理 MLU 上的张量和网络算子的运算。 Cambricon PaddlePaddle 会基于CNNL 库在 MLU 后端实现常用网络算子的计算,并完成数据拷贝。
三、网络结构
文本检测任务:输入给定的图像,找出文本区域。
DBNet 是一个基于分割的文本检测算法,该算法提出了可微分阈值 Differenttiable Binarization module (DB module),使用动态阈值来区分文本区域和背景。
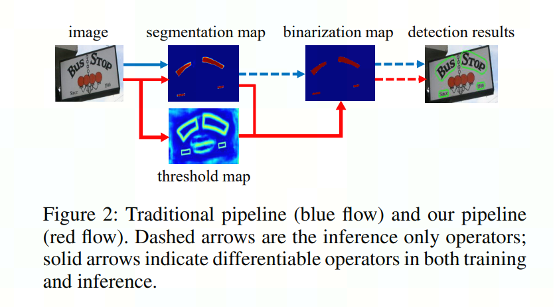
* 图片来自论文 Real-time Scene Text Detection with Differentiable Binarization
-
蓝色箭头描述的是基于分割的普通文本检测算法流程,该方法得到分割结果后采用一个固定的阈值得到二值化分割图,最后使用一些像素聚类操作得到文本区域。
-
红色箭头描述的是 DBNet 算法流程,不同点在于 DBNet 有个阈值图,通过网络去预测图片每个位置处的阈值,而不是使用一个固定的值,能更好的分离文本背景和前景。
DBNet 网络结构:
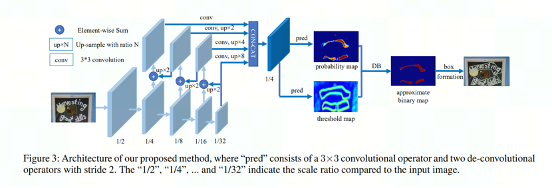
* 图片来自论文 Real-time Scene Text Detection with Differentiable Binarization
-
Backbone 网络:负责提取图像的特征。
-
RSEFPN 网络:引入残差结构和通道注意力机制,提升特征图的表征能力。
-
Head 网络:计算文本区域概率图。
四、模型训练

-
【工程准备】:安装依赖环境,下载源码、数据集和模型等。
-
【移植修改】:使用寒武纪 MLU 进行训练与使用 Intel CPU/Nvidia GPU 训练相同,当前 Paddle MLU 版本完全兼容 Paddle CUDA 版本的API,直接使用原有的 GPU 训练命令和参数即可。
-
【训练】:本文提供了4种训练方式:
-
Training: 基于数据从头开始训练
-
From pretrained training:基于原始代码权重文件进行训练
-
Resume Training:在上次训练基础上继续训练
-
Single machine multi-card training:单机多卡训练
-
【精度验证】:提供脚本测试训练的精度。
五、相关链接
实验代码仓库:https://gitee.com/cambricon/practices
Modelzoo仓库:https://gitee.com/cambricon/modelzoo