语音识别
一、示例简介
1. 应用场景
在科技高速发展的时代,对于语音分析的要求越来越高,而语音识别系统却能解决部分音频不易分析(检索等操作)的问题,可应用在图像压缩、直播平台、特效处理、图像复原等多个场景中。
2. 实现功能
基于市场部分的要求,本系统仅实现了语音转字幕的开发,并且在web端提供了可供交互的展示界面,用户可通过展示界面完成数据的传输与处理结果的展示。
二、方案优势
1. 使用寒武纪智能处理卡,为端、云侧推理提供的强大运算能力支撑,并具备视频解码功能。
2. 基于cnstream开源框架,以模块的方式组织功能,可以根据具体场景方便地增加或替换模块,具有很高的扩展性。
3. 根据寒武纪硬件进行优化,通过多batch等方式,充分利用多个MLU core进行平行处理。
4. 直接加载寒武纪离线模型,脱离深度学习框架,直接调用寒武纪运行时库(CNRT),具有很高的执行效率。
三、适配规格
1. 硬件平台
寒武纪MLU270系列智能处理卡
寒武纪 MLU270采用寒武纪MLUv02架构,可支持视觉、语音、自然语言处理以及传统机器学习等多样化的人工智能应用,更为视觉应用集成了充裕的视频和图像编解码硬件单元。
MLU270集成了寒武纪在处理器架构领域的一系列创新性技术,处理非稀疏深度学习模型的理论峰值性能提升至上一代思元100的4倍,达到128TOPS(INT8);同时兼容INT4和INT16运算,理论峰值分别达到256TOPS和64TOPS;支持浮点运算和混合精度运算。

|
最低配置 |
1张MLU270对应总共不少于8个CPU核心 |
不少于16GB内存 |
案例展示
|
服务器厂商 |
型号 |
高度 |
CPU平台 |
MLU板卡 |
插卡数 |
|
Inspur |
NF5468M5 |
4U |
2* Intel Xeon Scalable Processor |
MLU270-X5K |
8 |
|
NF2180M3 |
2U |
FT2000plus |
MLU270-A4K |
4 |
|
|
GreatWall |
DF720 |
2U |
FT2000plus |
MLU270-A4K |
2 |
2. 软件环境
依赖寒武纪驱动(Cambricon Driver),寒武纪软件(Cambricon Neuware)中的编解码库(CNCodec)、运行时库(CNRT)、CNDEV、CNDRV、CNML、CNPlugin等。
四、功能介绍
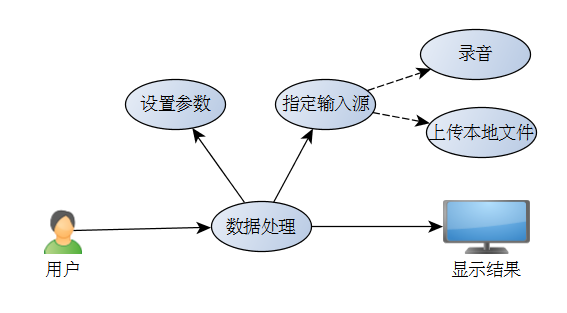
语音识别系统的系统用例图,如下图所示:
五、实现方案
1. 系统框架图
语音识别系统可由Infer Server和Web Server两部分组成,
Infer Server采用C++和Bang C进行开发,音频文件解码后先进行特征提取,然后交由Bang C编写的网络处理,
最后得到该音频对应的字幕。
Web Server采用Node.js框架进行开发,解析HTTP请求,完成数据的解析与封装,实现与infer Server之间的通信。
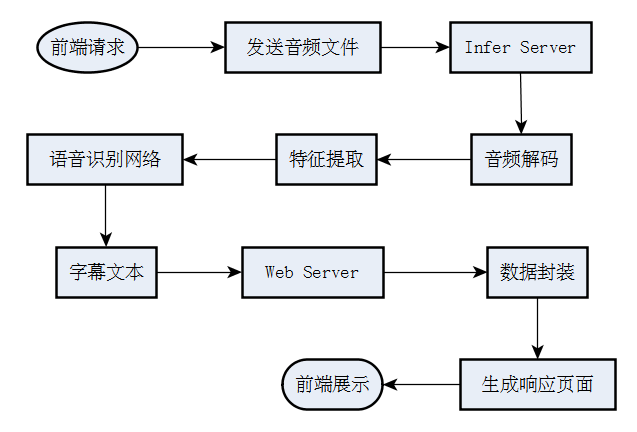
2. 流程图
整个系统的处理流程主要包含Web Server和Infer Server的处理部分,以及两者之间的数据通信部分
其中Web Server的主要功能是提供处理数据的接收以及处理结果的展示服务,相当于一个数据中转站,
而Infer Server则是提供实际的网络推理服务,完成特征提取和识别,是系统中最重要的部分
图像增强系统的流程图如下:
3. 解释说明
整个流程包括以下环节:请求的解析与响应、数据解析与封装、进程通信、音频解码、特征提取以及语音识别网络等。
1)请求的解析与响应
请求可分为两种类型的请求,分别是GET和POST类型的请求
其中GET类型的请求,是将携带的信息放在HTTP链接中传递到Web后端,这种方式的请求携带的数据量一般都小,适合数据是地址链接的
而POST类型的请求,是将数据以表格的方式存放在HTTP请求的body内,这种方式能够传递较大的数据信息,适合以图像视频文件传递的
对于响应,Web Server在收到Infer Server处理的结果后,生成对于响应页面进行发送
2)数据解析与封装
数据的解析与封装主要应用在Web Server与Infer Server之间的通信中。
3)进程通信
Web Server 和 Infer Server是两个独立的进程,它们之间采用socket套接字进行通信,传递在数据解析和封装中所述的数据信息
socket套接字包含client端和server端,在Web Server和Infer Server都会存在一个socket的server,每次消息传递时都会新建一个client与对应的server进行连接,完成进程的通信
4)音频解码
解码使用从Kaldi中提取出的模块在CPU上进行
5)特征提取
特征提取部分是从Kaldi中提取的代码,能够提取fbank、mfcc等多种特征
6)语音识别网络
由Bang C编写的网络组成,该网络主体部分是Transformer模型,来源于espnet提供的结构,能够将特征识别出文字
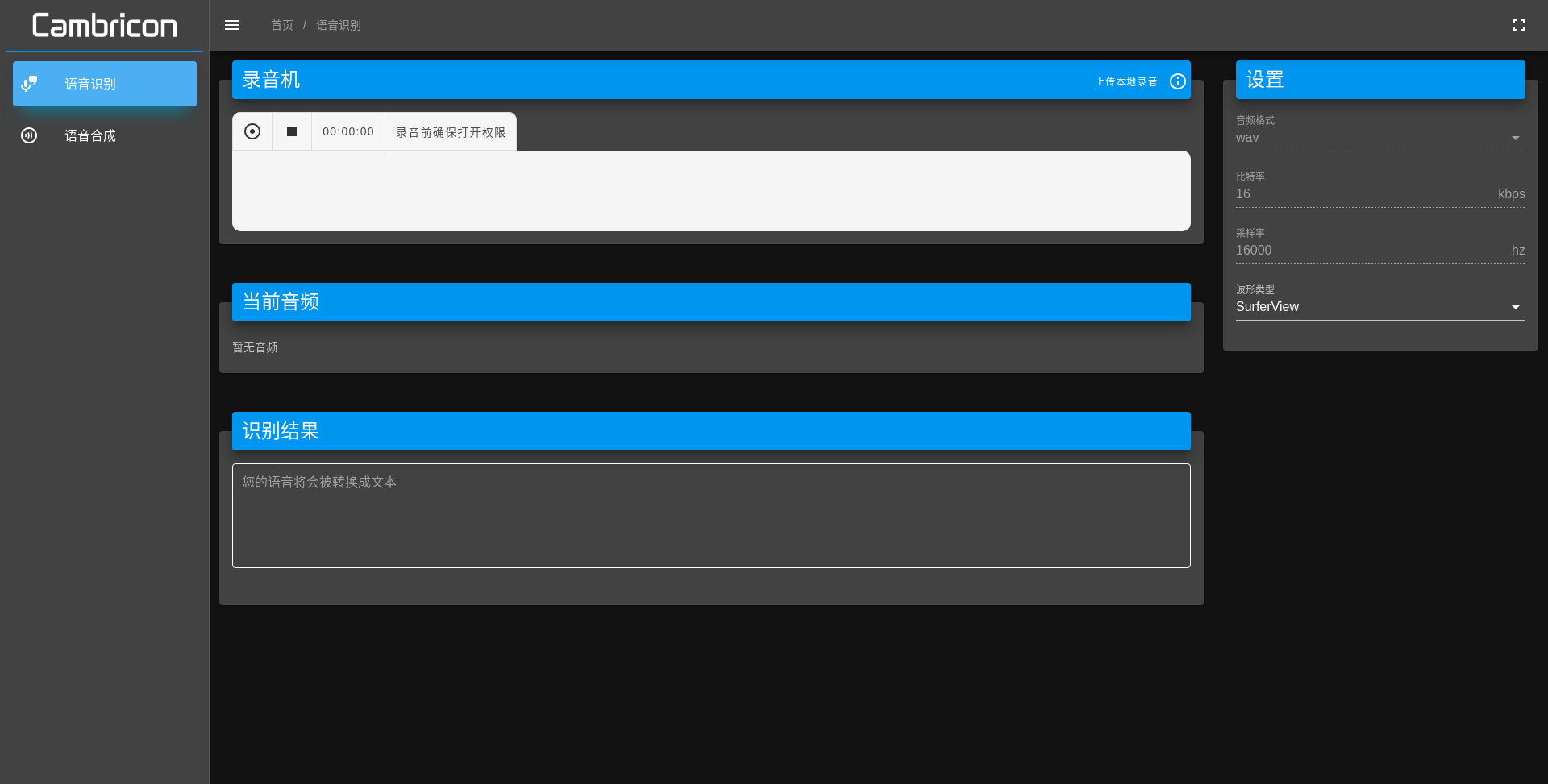
六、效果展示
七、相关资源
代码将在GitHub(https://github.com/Cambricon)上开源,感谢您的关注。
Espnet: https://github.com/espnet/espnet