推荐系统
一、示例简介
推荐系统是解决大数据时代信息过载问题的有效方法,因此各大电商平台、视频播放平台、新闻平台、社交平台等都依赖于有效的推荐系统。本文档是以电商平台为背景,基于MLU服务器的推荐系统解决方案的方案。
- 本方案基于经典的三步架构(召回->排序->业务调控)进行设计
- 本方案目前只考虑个性化推荐,其他推荐方式后面可根据需求添加
- 本方案暂时未考虑新用户及新商品的冷启动问题
二、方案优势
1. 使用寒武纪智能处理卡,为推理提供的强大运算能力支撑。
2. 根据寒武纪硬件进行优化,通过多batch等方式,充分利用多个MLU core进行平行处理。
3. 直接加载寒武纪离线模型,脱离深度学习框架,直接调用寒武纪运行时库(CNRT),具有很高的执行效率。
三、适配规格
1. 硬件平台
寒武纪MLU270系列智能处理卡
寒武纪 MLU270采用寒武纪MLUv02架构,可支持视觉、语音、自然语言处理以及传统机器学习等多样化的人工智能应用,更为视觉应用集成了充裕的视频和图像编解码硬件单元。
MLU270集成了寒武纪在处理器架构领域的一系列创新性技术,处理非稀疏深度学习模型的理论峰值性能提升至上一代思元100的4倍,达到128TOPS(INT8);同时兼容INT4和INT16运算,理论峰值分别达到256TOPS和64TOPS;支持浮点运算和混合精度运算。

|
最低配置 |
8张MLU270对应总共不少于16个CPU核心 |
不低于2倍加速卡缓存容量的系统内存,256GB |
|
建议配置 |
8张MLU270对应总共不少于32个CPU核心 |
不低于3倍加速卡缓存容量的系统内存,384GB |
|
4张MLU270对应总共不少于16个CPU核心 |
不低于3倍加速卡缓存容量的系统内存,192GB |
案例展示
|
服务器厂商 |
型号 |
高度 |
CPU平台 |
MLU板卡 |
插卡数 |
|
Inspur |
NF5468M5 |
4U |
2* Intel Xeon Scalable Processor |
MLU270-X5K |
8 |
|
NF2180M3 |
2U |
FT2000plus |
MLU270-A4K |
4 |
|
|
GreatWall |
DF720 |
2U |
FT2000plus |
MLU270-A4K |
2 |
2. 软件环境
依赖寒武纪驱动(Cambricon Driver),寒武纪软件(Cambricon Neuware)中的编解码库(CNCodec)、运行时库(CNRT)、CNDev、CNDrv、CNML、CNPlugin等。
四、功能介绍
推荐系统是实现基于亚马逊开源数据集 并且运行在寒武纪MLU上的一套推荐服务。
整套推荐系统主要包括以下几个模块:推荐服务,数据库,算法,前端页面以及dataflow
-
前端UI负责接收并发送用户请求,接收并展示推荐结果
-
存储分为两部分,DB中存储由日志采集得来的原始数据,整理成表存储在数据库DB中;KV中存储经过模型或其他机制计算得到的中间结果,在线处理时可从KV存储中获取数据。
-
离线处理流程
-
定期进行离线计算,包括离线推荐结果(热门、兴趣等),embedding等,更新KV存储
-
-
在线处理流程
-
日志采集:采集用户行为数据进行整理并写进DB存储(这里只实现了浏览行为)
-
Recall模块根据不同的算法提取候选结果,作为候选集发送给Ranking模块
-
Ranking模块使用算法对候选集的Item进行排序,将排名靠前的Item作为候选集发送给业务调控模块
-
业务调控模块根据具体规则(比如广告产品靠前,剔除评分过低的产品等)对候选集作进一步调整,还可以包含推荐解释等功能,并将最终推荐结果返回给UI展示
-
系统整体结构图如下所示:

五、实现方案
整个实现方案包括算法、数据库、Dataflow、推荐服务及前端页面五个部分。
5.1. 算法
算法是整个推荐系统的核心部分,推荐系统中包含两个深度学习算法,分别负责粗排和精排。
一个是NCF(Neural Collaborative Filtering)算法,用作召回数据。
另一个是Wide&Deep/DIEN,用于计算CTR结果。
这个模块提供了以下几个功能:
-
模型的源码实现
-
训练模型使用的脚本
-
每个模型基于pb的推理接口
-
每个模型的测试代码,包括各种性能指标测试代码
5.1.1 NCF
NCF 是深度协同过滤网络,在推荐系统中根据用户属性以及历史行为提供一系列候选数据集
NCF的开源实现位于: https://github.com/hexiangnan/neural_collaborative_filtering
5.1.1.1接口
模型输入:userid,itemid
模型输出:items(协同过滤的结果,目前训练的最大是50个)
5.1.2 Wide&Deep/DIEN
Wide&Deep/DIEN 根据用户历史行为对每一个商品进行CTR预估。
模型的开源实现: https://github.com/mouna99/dien
5.1.2.1 接口
模型输入:userid,itemid,item categoery,[history_behavior_item, ....], [history_behavior_item_catgoery]
模型输出:CTR
5.1.2.2 精度
|
模型 |
pltform |
max behavior number |
batch_size |
threshold |
accuracy |
mean_accuracy |
precision |
recall |
auc |
|
Wide |
MLU 270 |
2 |
1 |
0.5 |
0.7029 |
0.7029 |
0.7261 |
0.6517 |
0.7783 |
|
WIde |
MLU 270 |
2 |
5 |
0.5 |
0.7029 |
0.7029 |
0.7261 |
0.6517 |
0.7783 |
|
Wide |
MLU270 |
2 |
10 |
0.5 |
0.7029 |
0.7029 |
0.7261 |
0.6517 |
0.7783 |
5.2 数据库
推荐系统是大数据时代信息过载问题的有效方法,因此有效数据还是需要依托数据库。
数据库表的设计会影响到上层软件的复杂度以及整个系统的实时性。
数据库是由关系型数据库(mysql)以及kv数据库(redis)组成的,完成不同的功能。
这个模块提供了以下几个功能:
- 解析并过滤原始数据集并录入数据库的脚本
- 数据库中各个table的设计
- python访问数据库的接口
5.2.1 关系型数据库
关系型数据库采用的mysql开源数据库。
mysql中存放用户信息、商品信息、用户评价信息以及用户历史行为信息
mysql 中一共包含四个database,包括user(用户信息), item_categories(商品信息),reviewer(用户评价信息),user_behavior(用户历史行为信息)。
user
|
Field |
Type |
Null |
Key |
Default |
Extra |
|
id |
int(11) |
NO |
PRI |
NULL |
auto_increment |
|
user id |
varchar(255) |
NO |
|
NULL |
|
|
user name |
varchar(255) |
YES |
|
NULL |
|
|
password |
varchar(255) |
YES |
|
NULL |
|
item_categories
|
Field |
Type |
Null |
Key |
Default |
Extra |
|
id |
int(11) |
NO |
PRI |
NULL |
auto_increment |
|
item id |
varchar(255) |
NO |
|
NULL |
|
|
title |
varchar(1024) |
YES |
MUL |
NULL |
|
|
price |
float(10,3) |
YES |
|
NULL |
|
|
imgurl |
varchar(2048) |
YES |
|
NULL |
|
|
main categories |
varchar(255) |
NO |
|
NULL |
|
|
sub categories |
varchar(255) |
YES |
|
NULL |
|
|
description |
text |
YES |
|
NULL |
|
reviewer
|
Field |
Type |
Null |
Key |
Default |
Extra |
|
id |
int(11) |
NO |
PRI |
NULL |
auto_increment |
|
item id |
varchar(255) |
NO |
|
NULL |
|
|
user id |
varchar(255) |
NO |
|
NULL |
|
|
user name |
varchar(255) |
YES |
|
NULL |
|
|
parent id |
varchar(255) |
YES |
|
NULL |
|
|
rating |
float(10,3) |
YES |
|
NULL |
|
|
summary |
varchar(1024) |
NO |
|
NULL |
|
|
content |
text |
NO |
|
NULL |
|
|
helpful |
varchar(255) |
YES |
|
NULL |
|
|
date |
varchar(255) |
YES |
|
NULL |
|
User_behavior
|
Field |
Type |
Null |
Key |
Default |
Extra |
|
id |
int(11) |
NO |
PRI |
NULL |
auto_increment |
|
item id |
varchar(255) |
NO |
|
NULL |
|
|
categories |
varchar(255) |
NO |
|
NULL |
|
|
behavior |
int(3) |
NO |
|
NULL |
|
|
time |
timestamp |
NO |
|
CURRENT_TIMESTAMP |
on update CURRENT_TIMESTAMP |
5.2.2 KV数据库
KV数据库使用的是redis 来完成的。
基于KV数据库实现了热门商品点击次数。
5.2.3 接口设计
实现了mysql_wrapper, redis_wrapper两个类,来访问mysql以及redis
5.3 Dataflow
Dataflow模块主要是为了可以使算法运行在MLU上,通过MLU的运算加速计算结果,减少CPU的负荷,同时提高系统的实时性。
整个模块的开发是基于Cambricon 的neuware 包以及easydk 实现的。
这个模块提供以下几个功能:
- 基于MLU的推理的C++ 接口
- 针对C++接口的测试程序以及C++接口性能测试程序,用于对比pb的性能数据
- 基于MLU推理的python接口
5.3.1 C++接口
dataflow 模块由三个部分组成,Recall ,ranking 负责不同的算法逻辑以及ModelRunner 负责与底层硬件交互(包括内存的分配及网络输入(H2D),网络结果拷出(D2H等)。
Recall 提供协同过滤结果 ,使用的是NCF 网络,包括前处理,后处理以及网络运算等。
Ranking 模块提供CTR预估结果,包括网络前处理,网络的后处理,embedding层的实现等。
5.3.2 Python接口
dataflow模块提供了python接口掉用,封装在dataflow module 中。
通过import dataflow 可以访问module 中的方法。
python 接口是通过pybind11封装。
5.4 推荐服务
推荐服务是串起整个系统部分,包括和前端的交互,数据库操作,调用dataflow计算结果。
web服务框架使用的是Flask 框架搭建,并提供Restful API
整个流程包括响应用户前端页面操作,调用召回计算结果提供粗排数据,合并多路召回数据并调用ranking 计算结果,返回ranking 结果给前端页面展示给用户。
这个模块提供以下几个功能:
- web框架
- 日志采集及数据清洗,以及录入到数据库
- Rsetful 接口设计,供前端调用
- 不同的推荐服务,包括基于用户历史行为的推荐服务,基于商品的推荐服务
- 搜索服务
5.4.1 搜索
搜索也是推荐的一部分,用户可以通过关键字来进行商品搜索,算法会在数据库中进行完整商品进行搜索,然后通过计算从数据库中获得每个商品的CTR,再以CTR进行排序返回给请求。
接口以resetful 返回。
5.4.2 推荐
推荐服务一共集成了两种推荐服务,基于用户历史搜索的推荐服务,根据用户点击商品的推荐服务(两者均为在新进行推荐)。
两种推荐服务均以restful 接口为用户提供返回结果。
5.4.3 web 框架
web框架使用的是Flask 搭建的,提供了与前端界面的交互操作。
5.4.4 日志清洗与录入
日志清洗模块主要是录入用户的历史行为到数据库中。
5.5 前端页面
前端页面主要是用来和用户进行交互的,只要做到能够有效的展示推荐服务,并且可以有效的推荐商品。
前端页面包含四个页面,用户登陆页面,搜索页面,商品详细信息,以及根据商品推荐的商品页面。
这个模块提供了以下几个功能:
- 用户登陆之后,发送推荐请求,得到后端反馈数据,并绘制推荐结果
- 用户登陆之后,可以进行相关商品的搜索,并且展示搜索结果
- 用户点击商品链接,显示商品的详细信息,并发送推荐请求,得到请求之后绘制推荐结果
- 每个页面都可以直接跳转到首页
- 每个页面都显示用户登陆状态,并且均可以跳转到登陆页面
六、效果展示
用户未登录页面
用户登录页面
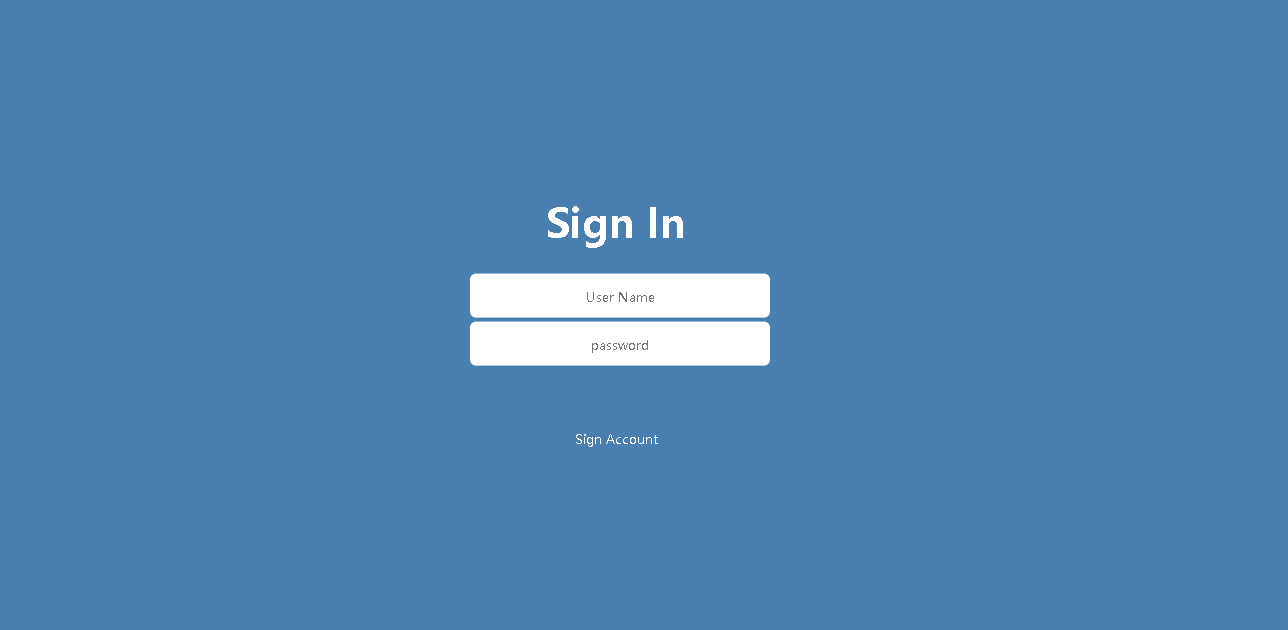
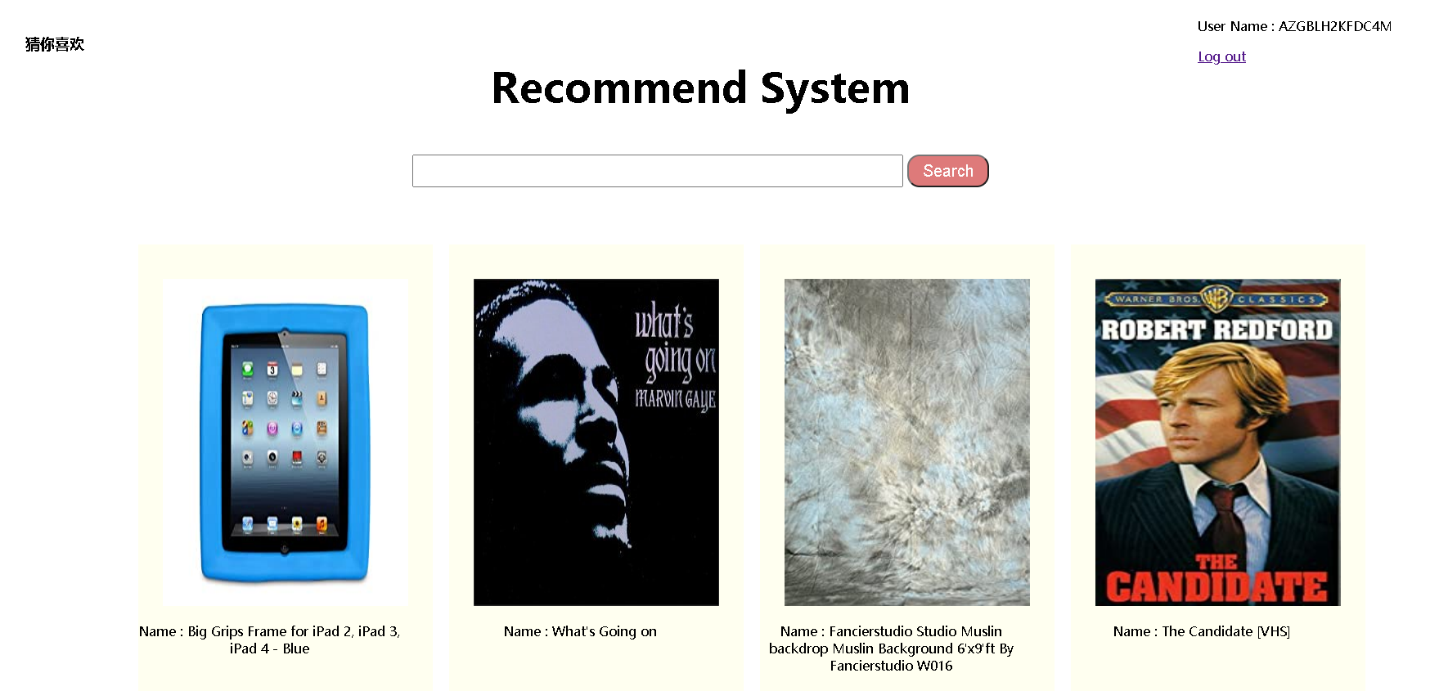
用户登录后首页展示的猜你喜欢页面
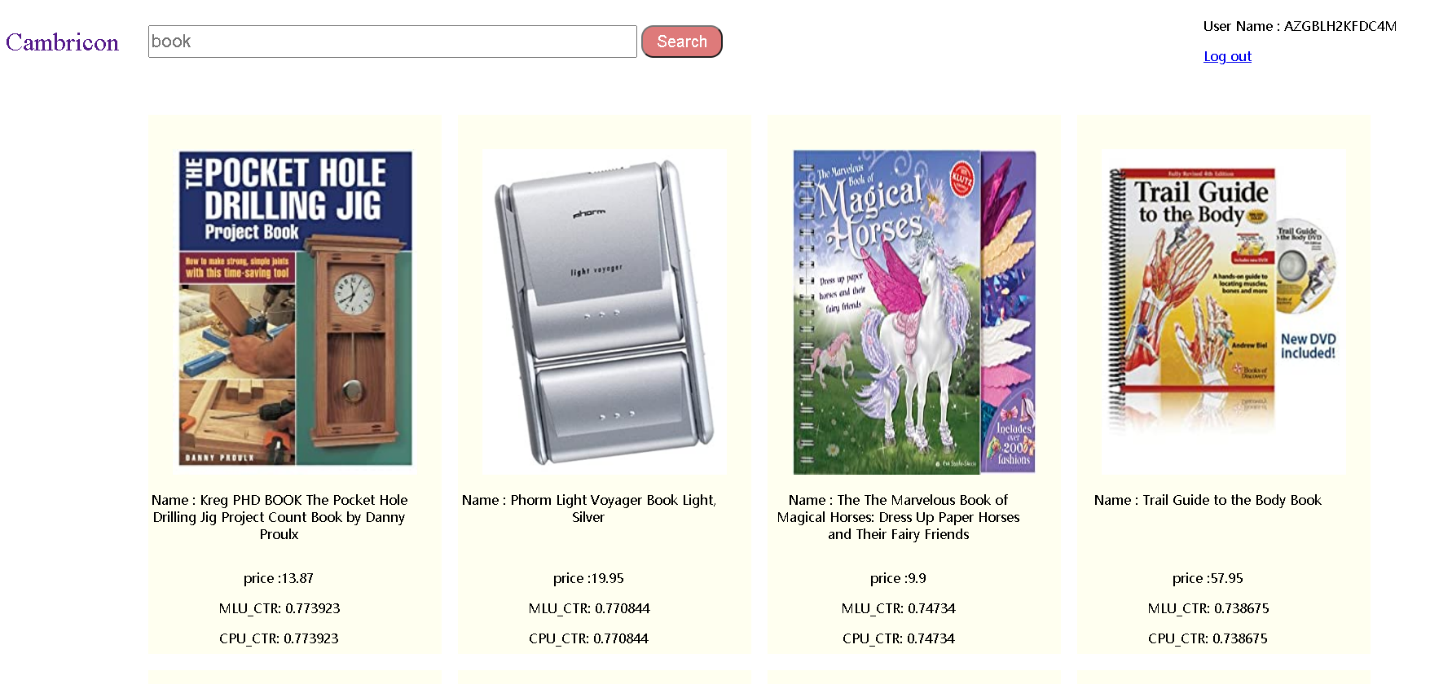
搜索页面
商品详细信息展示页面

根据点击的商品进行的推荐

七、相关资源
将在GitHub(https://github.com/Cambricon)上开源,感谢您的关注。